相关资料
可参考大话数据结构中串的一节KMP匹配 Algorithm Implementation/String searching/Knuth-Morris-Pratt pattern matcher 字符串匹配的KMP算法 主要参考大神阮一峰进行学习的,下面均来自于其博客。 The Knuth-Morris-Pratt Algorithm in my own words
核心思路是将比较过的位置不要继续进行比较,其中使用《部分匹配表》(Partial Match Table)既可以解决这个问题。已知空格与D不匹配时,前面六个字符”ABCDAB”是匹配的。查表可知,最后一个匹配字符B对应的”部分匹配值”为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
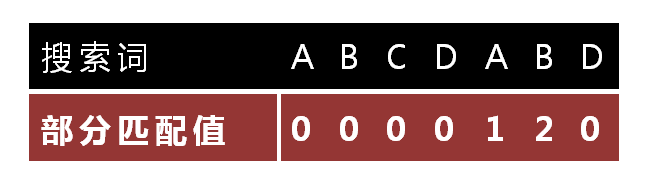

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:”前缀”和”后缀”。 “前缀”指除了最后一个字符以外,一个字符串的全部头部组合;”后缀”指除了第一个字符以外,一个字符串的全部尾部组合。
“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
“部分匹配”的实质是,有时候,字符串头部和尾部会有重复。比如,”ABCDAB”之中有两个”AB”,那么它的”部分匹配值”就是2(”AB”的长度)。搜索词移动的时候,第一个”AB”向后移动4位(字符串长度-部分匹配值),就可以来到第二个”AB”的位置。

# Knuth-Morris-Pratt string matching
# David Eppstein, UC Irvine, 1 Mar 2002
#from http://code.activestate.com/recipes/117214/
def KnuthMorrisPratt(text, pattern):
'''Yields all starting positions of copies of the pattern in the text.
Calling conventions are similar to string.find, but its arguments can be
lists or iterators, not just strings, it returns all matches, not just
the first one, and it does not need the whole text in memory at once.
Whenever it yields, it will have read the text exactly up to and including
the match that caused the yield.'''
# allow indexing into pattern and protect against change during yield
pattern = list(pattern)
# build table of shift amounts
shifts = [1] * (len(pattern) + 1)
shift = 1
for pos in range(len(pattern)):
while shift <= pos and pattern[pos] != pattern[pos-shift]:
shift += shifts[pos-shift]
shifts[pos+1] = shift
# do the actual search
startPos = 0
matchLen = 0
for c in text:
while matchLen == len(pattern) or \
matchLen >= 0 and pattern[matchLen] != c:
startPos += shifts[matchLen]
matchLen -= shifts[matchLen]
matchLen += 1
if matchLen == len(pattern):
yield startPos